Таки доделал програмку на Питоне, рисующую спектр сигнала и автоматически считающую КНИ+шум и ОСШ. Попутно узнал, как водится, много нового. За что люблю Питон — так это за то, что программа занимает менее 40 строк. На тех же Сях я бы усрался это рисовать. Даже на Шарпах бы усрался.
Программе скармливается звуковой файл с сигналом частотой в 1 kHz, сгенерированный программой Adobe Audition (в девичестве Syntrillium CoolEdit). Но можно взять и бесплатный Audacity, результат будет точно такой же. Программа читает файл, берёт значение с наибольшим пиком и даёт ему обозначение в 0 децибел. Остальное, соответственно, отрицательные величины. Подсчитывается среднеквадратичное значение всего, что не сигнал, и делится на уровень сигнала. Получается КНИ+шум (THD+N). Потом считаем ОСШ (отношение сигнал/шум, SNR) в децибелах: 20log10(сигнал / шум)
Вот так выглядит анализ звукового файла с сигналом 1 kHz, разрешением 16-бит, частота дискретизации — 48 kHz:
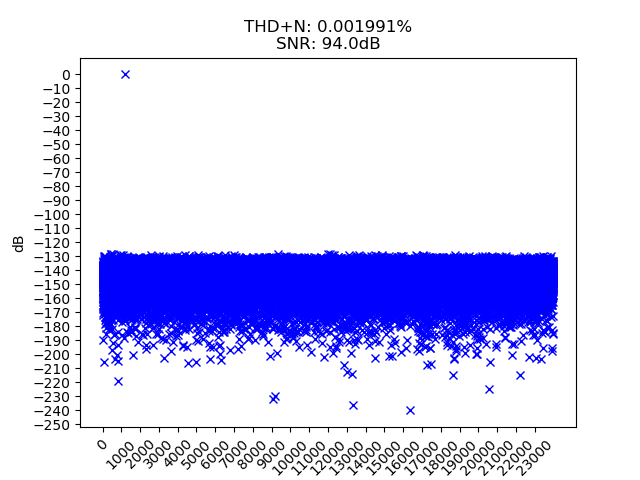
Это весьма близко к теоретическому идеалу — в идеале, разрешение 16 бит может дать ОСШ в 96.3 dB. Но у меня не идеал, так как я использую чуть менее, чем 16 бит — ибо если генерировать синусоиду с уровнем в 0 dB (т.е. по-максимуму), то почему-то уже лезут нелинейные искажения. Так что я создаю её с уровнем в -0.1 dB, минимальным отступлением от максимума, которое мне даёт делать Audition. В любом случае, 94 dB — это дохрена.
КНИ в 2 тысячных процента это тоже прекрасно. Без приборов этого никто никогда не увидит, искажения начинают быть слышимыми, когда уже вплотную приближаются к 1%, хотя это сильно зависит от того, что именно слушаем: если чистые синусоиды, то искажения начинают быть заметными гораздо раньше, а если в качестве тестового материала брать альбомы фифтисентов и прочих, то там можно и 10% искажений не услышать. Что не означает, что аппаратура, дающая КНИ в 0.05%, ничем не лучше аппаратуры, дающей 0.1% — она лучше; просто в реальности ушами этого ни один живой человек не услышит.
А теперь — снова пнём формат MP3 🙂 Никто как-то вот не задумывается о том, что они слушают в тысячедолларовых деревянных наушниках, подключённых к внешним усилителям класса А за семьсот долларов, обещающим КНИ в 0.00045%
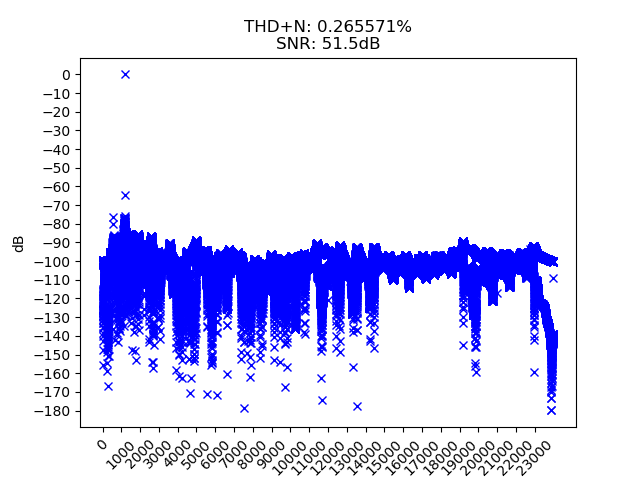
А между тем это реалии MP3 с битрейтом в 192 килобита/сек:
А это — 320 килобит/сек:
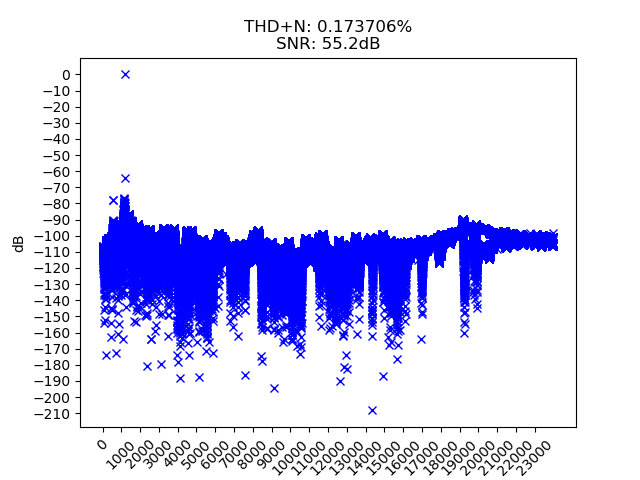
Получше, конечно, чем 192 kbps, но всё равно проседание качества очень налицо — происходит серьёзное ужимание динамического диапазона (я в курсе, что ДД и ОСШ это не вполне одно и то же, но они связаны). На некотором материале (например, классическая музыка, обладающая большим динамическим диапазоном) это может быть очень заметно. На 192 килобитах так это точно заметно, тихая партия скрипки сопровождается скрежетом артефактов сжатия с потерями — собственноушно, так сказать, слышал. Дальнейшее увеличение битрейта после 320 килобит/с, кстати, уже ничего не даёт — ОСШ так и остаётся в районе 55 децибел.
Ещё надо будет попинать винилофильство и прочее плёнколожество, но это в другой раз 🙂